Microsoft’s Outage: The Day the Cloud Wept
Hello, my dear readers! Namaste! Buckle up because today we’re diving into an epic saga that’s straight out of a Bollywood thriller! Microsoft’s latest adventure in the cloud made headlines for all the wrong reasons. Grab your chai and samosas because this one’s a blockbuster!
The Incident
Picture this: It’s July 19, 2024, a regular day where we’re all minding our business, happily clicking away on our Microsoft services. Suddenly, BAM! Access denied. Social media erupts, tech forums go ablaze, and somewhere, a Microsoft engineer is having a mini heart attack. Microsoft confirmed the outage and scrambled to figure out why the digital sky was falling. Spoiler alert: We’re way too dependent on this tech stuff.
Ever wondered how life would be if our tech suddenly stopped working?
Root Causes and Technical Details
The plot thickens as we discover that the outage was primarily triggered by a faulty update released by CrowdStrike, a cybersecurity firm. This update, meant for their Falcon sensor software, led to widespread system crashes, aka the Blue Screen of Death (BSOD) on Windows machines globally. The issue stemmed from a defect in the configuration update, causing operating systems to malfunction and needing manual intervention to resolve.
Note: CrowdStrike’s Falcon sensor is a widely-used endpoint protection solution designed to detect and prevent security breaches.
Digging Deeper into the Update Issue
The specific update from CrowdStrike had a misconfiguration in the Falcon sensor’s interaction with the Windows kernel. This led to conflicts in system processes, triggering a cascade of errors in the Windows kernel. Critical system processes failed, resulting in the infamous BSOD, rendering systems inoperable. Affected systems needed manual intervention to roll back the update or apply a subsequent patch from CrowdStrike, significantly slowing the recovery time.
Can one quirky update quack the quality of countless computing queries? Apparently, yes!
Image: A Faulty Update Process
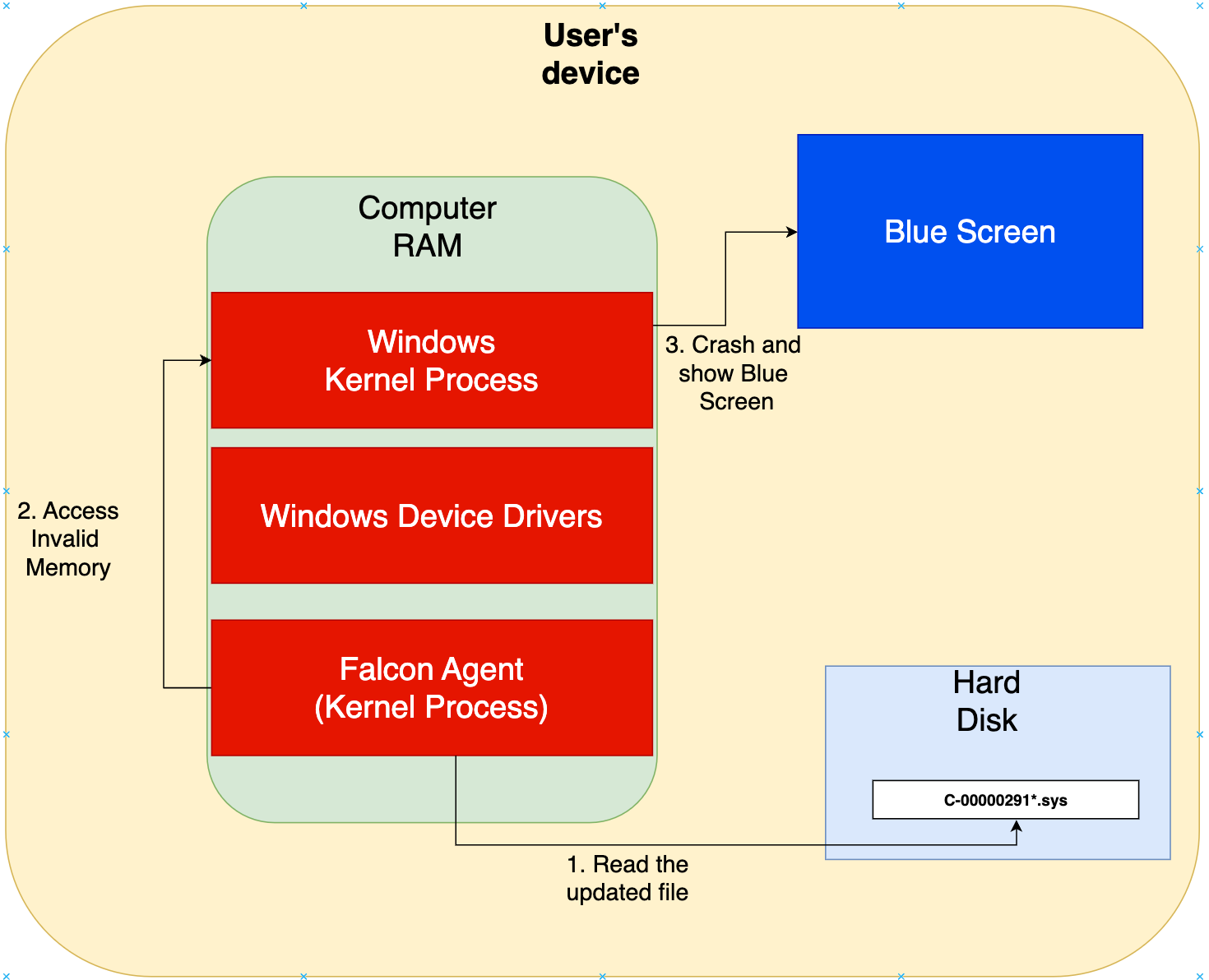
Affected Services and Regions
The impact of this digital disaster was vast:
- Services Impacted: Microsoft 365, Microsoft Teams, PowerBI, Azure services, Bing API, and services relying on these platforms, such as DuckDuckGo and ChatGPT. The widespread nature of the impact showed the critical role Microsoft services play in both business and personal computing.
- Regions Affected: The outage had a global reach, significantly impacting regions including EMEA (Europe, Middle East, Africa), Asia, and North America. Specific impacts were reported in the UK, South Africa, India, and the United States. This global footprint underscores the extensive reliance on Microsoft’s infrastructure.
Image: Representative Global Impact Map
Business and Operational Impact
The outage had severe repercussions across various sectors:
- Airlines: Check-in systems at major airports in India, including Mumbai and Delhi, were disrupted, affecting airlines like IndiGo, Akasa, and SpiceJet. I was personally affected by this as I was about to board a flight on the early morning of July 20th, but the flight got abruptly canceled, impacting my trip to North India in a big way. I had to waste almost two days due to this schedule change. While my personal loss was not much, I can imagine the loss it entails to so many individuals and businesses that were impacted.
- Healthcare: Hospitals had to cancel appointments and delay procedures due to the unavailability of critical Microsoft 365 services. The potential risks to patient care during such outages emphasize the need for robust contingency plans.
- Financial Services and Other Businesses: Companies relying on Microsoft Teams and other collaboration tools experienced significant operational delays, affecting productivity and business continuity. This interruption highlighted the importance of communication tools in maintaining business operations.
Ever experienced tech failure at the worst possible time?
Recovery and Mitigation Efforts
Microsoft and CrowdStrike worked intensively to resolve the issue. Microsoft redirected network traffic to mitigate the impact while CrowdStrike issued fixes for the faulty update. Despite these efforts, the recovery process was slow due to the necessity of manual interventions on affected endpoints. The meticulous and coordinated efforts to restore services showcased the complexity of modern IT infrastructures.
Image: Recovery and Mitigation at Endpoints

The Legacy of Microsoft’s Update Policies
This incident also brings to light the ongoing issues with Microsoft’s update policies. For years, users have expressed frustration over Microsoft’s often forced and sometimes poorly-timed updates. These updates, while intended to enhance security and functionality, have occasionally led to significant disruptions. The forced nature of these updates means that users sometimes have little control over when and how updates are applied, leading to unexpected downtime and, in this case, widespread system failures.
Do dense, difficult, daily downloads disrupt our digital duties? Definitely!
Isolation Mechanisms: Could They Help?
To mitigate the impact of such incidents, implementing robust isolation mechanisms could be beneficial. These mechanisms would isolate different parts of the system to prevent a single point of failure from cascading across the entire infrastructure.
Technical Details on Isolation Mechanisms
- Microservices Architecture: Adopting a microservices architecture can help isolate services and minimize the impact of a faulty update. In a microservices architecture, applications are broken down into smaller, independent services that can be deployed and managed separately. This isolation ensures that an issue in one service does not affect the entire system.
- Containerization: Using containers (e.g., Docker) can help encapsulate applications and their dependencies. Containers provide an isolated environment for each application, reducing the risk of conflicts and ensuring that issues within one container do not impact others. This approach also simplifies the rollback of updates, as containers can be easily reverted to a previous stable state.
- Virtual Machines (VMs): Virtual machines provide a higher level of isolation compared to containers. By running applications in separate VMs, it is possible to isolate faults and prevent them from spreading. VMs can be used to create isolated environments for testing updates before rolling them out to production.
- Network Segmentation: Implementing network segmentation can help isolate different parts of the infrastructure. By segmenting the network, it is possible to contain the spread of issues and protect critical systems from being affected by a fault in one segment.
- Feature Flags: Using feature flags allows organizations to enable or disable features dynamically. This can be particularly useful during updates, as it allows new features to be rolled out gradually and rolled back quickly if issues arise. Feature flags can help isolate the impact of new updates and minimize disruptions.
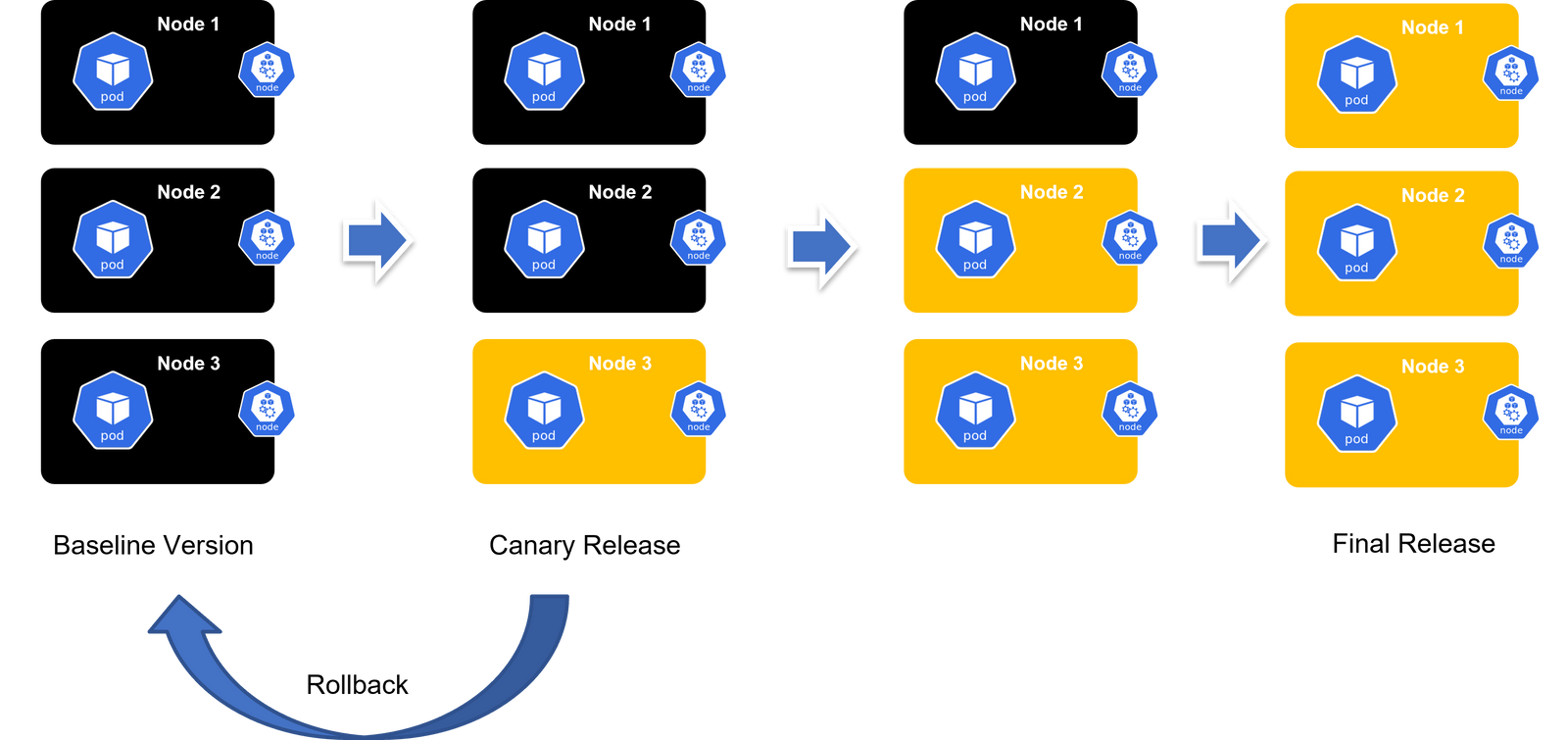
- Canary Deployments: Canary deployments involve rolling out updates to a small subset of users before a full deployment. This approach allows organizations to monitor the impact of the update on a limited scale and catch potential issues early. If problems are detected, the update can be halted or rolled back before it affects the entire user base.
Image: An Example Isolation Mechanism Diagram
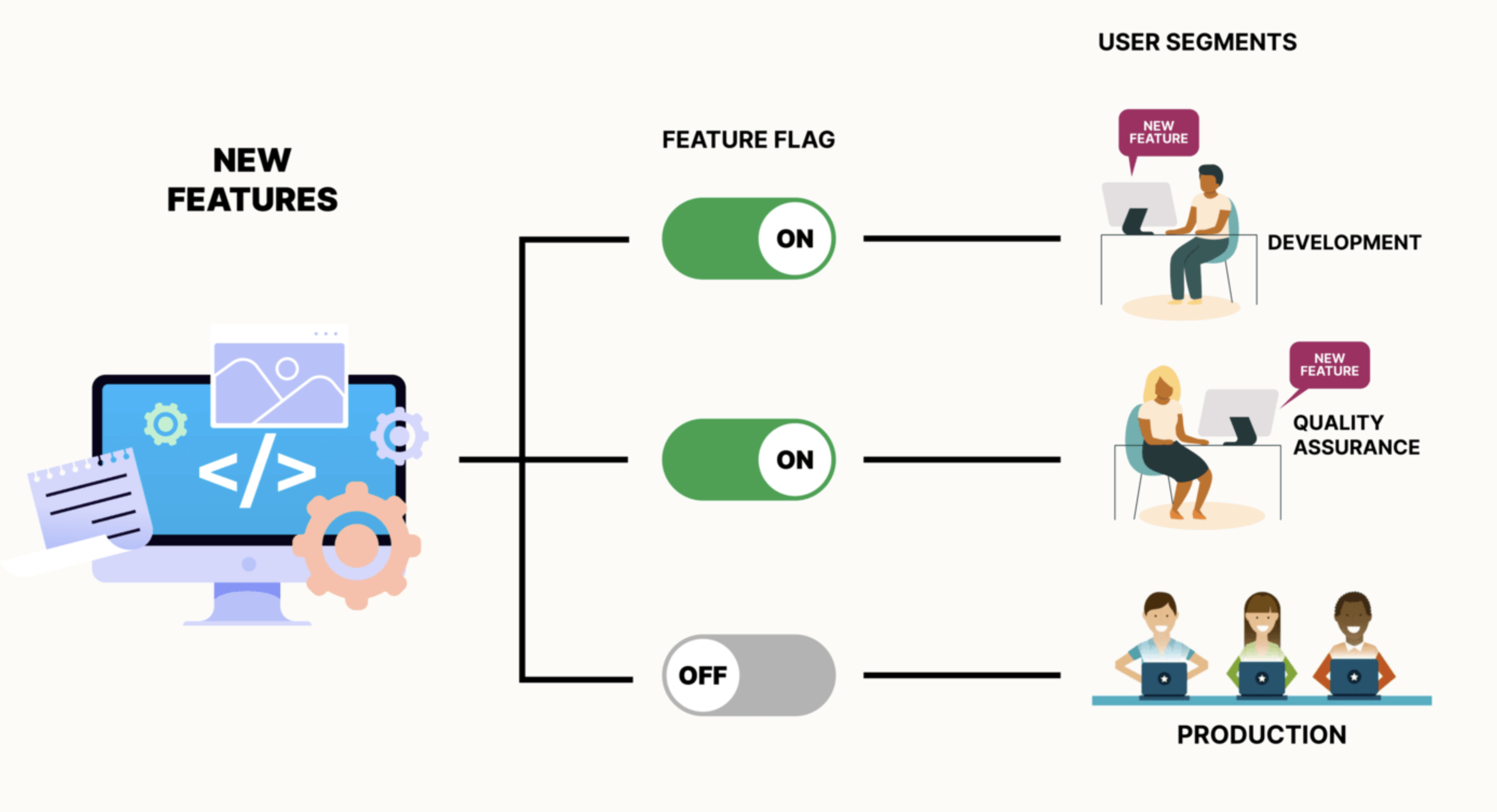
Why Weren’t These Mechanisms in Place?
Despite being aware of these mitigation techniques, several factors could explain why they weren’t effectively in place:
- Complexity of Implementation: Implementing isolation mechanisms across a vast and intricate IT infrastructure like Microsoft’s can be exceedingly complex. Ensuring seamless integration and operation without disrupting existing services requires substantial planning and resources.
- Legacy Systems: Many large organizations, including Microsoft, operate with a mix of modern and legacy systems. Integrating isolation mechanisms into older, less flexible systems can be challenging and resource-intensive.
- Cost and Resource Allocation: Ensuring robust isolation mechanisms requires significant investment in terms of both financial and human resources. Budget constraints and prioritization of other initiatives might delay the implementation of these mechanisms.
- Overconfidence in Current Systems: There might be an overconfidence in the existing resilience and redundancy plans, leading to a false sense of security. This can result in underestimating the potential impact of a widespread fault.
Have you ever wondered how many tech updates it takes to change a light bulb? Or to take down the cloud?
Lessons Learned and Future Implications
This incident underscores the vulnerabilities in relying heavily on cloud-based and third-party services. Key takeaways for businesses include:
- Diverse IT Infrastructure: Reducing reliance on a single service provider can help mitigate risks. Diversification can ensure that a failure in one system does not paralyze entire operations.
- Robust Cyber-Resilience Plans: Businesses should establish comprehensive disaster recovery and cyber-resilience strategies. These plans must be dynamic and regularly updated to address new types of threats.
- Regular Testing: Simulating potential outages and regularly testing fail-safes can prepare organizations for real-world disruptions. Regular drills and updates to contingency plans are crucial for preparedness.
Pseudo Code Example for Preventive Measures
To illustrate a preventive measure that could have helped mitigate the impact, here is a simple pseudo code example for implementing canary deployments and rollback mechanisms:
function deployUpdate(update) {
// Step 1: Deploy update to canary servers
for each server in canaryServers:
deploy(update, server)
monitor(server)
// Step 2: Monitor canary servers for issues
if all(canaryServers.status == 'healthy'):
// Step 3: Proceed with full deployment if no issues
for each server in productionServers:
deploy(update, server)
monitor(server)
else:
// Step 4: Rollback update if issues detected
for each server in canaryServers:
rollback(update, server)
notifyAdmin("Update rolled back due to issues detected in canary deployment")
}
function deploy(update, server) {
// Deploy the update to the server
server.apply(update)
}
function monitor(server) {
// Monitor the server for a set period to check for issues
wait(monitoringPeriod)
if server.status != 'healthy':
return false
return true
}
function rollback(update, server) {
// Rollback the update from the server
server.revert(update)
}
Image: Example of Canary Deployment
What Should Microsoft Do in the Future?
To prevent similar incidents, Microsoft should:
- Improve Update Testing and Rollout Processes: Enhance the rigor and scope of update testing to catch potential issues before they are deployed widely. Implement more phased rollouts to identify and mitigate problems early.
- Increase User Control Over Updates: Provide users with more control over when and how updates are applied. This includes options to defer updates and more transparent communication about the potential impacts of updates.
- Enhance Collaboration with Third-Party Vendors: Work closely with third-party vendors like CrowdStrike to ensure their updates are thoroughly tested and do not cause conflicts with Microsoft systems.
- Strengthen Disaster Recovery Protocols: Develop and regularly update comprehensive disaster recovery protocols to minimize downtime in the event of an outage. This includes faster rollbacks and automated recovery processes.
- Implement Isolation Mechanisms: Use microservices architecture, containerization, VMs, network segmentation, feature flags, and canary deployments to isolate and minimize the impact of faults.
What do you think Microsoft should prioritize to prevent such issues in the future?
Steps for Other Cloud Providers Like Google and Amazon
Google and Amazon, as other major cloud providers, should also take steps to avoid similar issues:
- Robust Multi-Layered Testing: Implement rigorous multi-layered testing for updates and new features to identify potential issues in various environments.
- User-Centric Update Policies: Adopt user-centric update policies that provide flexibility and transparency to users, allowing them to manage updates in a way that minimizes disruption.
- Cross-Vendor Collaboration: Foster collaboration with third-party vendors and other cloud providers to share best practices and improve overall cloud reliability.
- Proactive Incident Management: Develop proactive incident management strategies that include real-time monitoring, quick incident response, and efficient communication with users during outages.
The financial impact of this outage was significant, with estimates reaching approximately $16 million due to downtime across various services and regions. This event serves as a critical reminder of the importance of robust IT infrastructure and contingency planning in today’s interconnected digital landscape.
Do you think other cloud providers are better prepared to handle such incidents?
Conclusion
As cloud computing becomes increasingly integral to daily operations, the reliability of these services is paramount. Microsoft, like other cloud providers, continually invests in improving the robustness of its infrastructure. This outage, while disruptive, provides valuable insights for enhancing the resilience of cloud services. The proactive approach to resolving the issue and communicating with users will play a key role in maintaining trust and ensuring long-term reliability.
Stay tuned for more updates and insights as we continue to explore the rapidly changing landscape of technology. Your feedback and thoughts are always welcome!
Warm regards,
Bhargav
#MicrosoftOutage #CloudReliability #CyberSecurity #TechNews #Azure #Microsoft365 #CrowdStrike #BusinessContinuity #DisasterRecovery #ITInfrastructure #TechInsights #CloudComputing #DataSecurity #TechIndustry #ITStrategy #DigitalTransformation #CanaryDeployment #IsolationMechanisms
Resources and references
- TechXplore: Microsoft-CrowdStrike Outage Analysis
- Covers the chaos caused by a software update from CrowdStrike, affecting Microsoft Windows systems globally. It discusses broader implications for IT infrastructure and cybersecurity.
- TechXplore Article
- TechCrunch: Microsoft Says 8.5M Windows Devices Were Affected by CrowdStrike Outage
- Discusses the scale of the outage, including the number of affected devices and Microsoft’s steps to manage the crisis, offering insights into the response and implications for businesses.
- TechCrunch Article
- Engineering at Scale: Blue Screens to Blackouts
- Narrates the events leading to the outage, emphasizing technical failures and recovery efforts.
- Blue Screens to Blackouts: The Story
- Digital Development and Public-Private Partnerships
- Discusses the importance of digital development and the role of public-private partnerships in enhancing global digital infrastructure and resilience.
- Digital Development and Public-Private Partnerships
- Prepare for a Cloud Outage
- Offers a guide on best practices for surviving cloud outages, emphasizing steps businesses can take to improve resilience and ensure continuity.
- Prepare for a Cloud Outage.
- Medium: Feature Flags in Software Development
- Explains how feature flags can be used to manage software updates effectively, reducing the risk of system failures.
- Feature Flags: Modifying Application Behavior Without Altering Code
- Devtron: Understanding Canary Deployment Strategy
- Discusses the canary deployment strategy as a method for safely rolling out updates and minimizing risk, enhancing system reliability.
- Canary Deployment Strategy
Liked...? Do share on...
Twitter Facebook
Leave a Comment